Usually Voice Converters use a set of training and testing example pairs to train a Machine Learning model like a Gaussian Mixture Model (GMM) or Deep Neural Network (DNN). In many edge devices or applications, it is impractical to acquire this data. In our project we propose a method to remove the need to collect audio samples from the user by combining a Deep Speech implementation with a Tacotron implementation. Consequently, we are able to convert input speaker's audio signal to text and used this text to synthesize speech in the voice that Tacotron was trained on. In addition, we show that our proposed pipeline also significantly reduces the need to train on the output user's voice. Last of all, we incorporate the initial project proposal of reducing model size and computational cost by pruning the model, quantizing the weights and creating heap maps.
SECTION I: Optimizing a model for size and speed
The model was optimized for speed and performance by reducing model size and computational cost by pruning the model, quantizing the weights and creating heap maps. Trimming removes train only nodes for faster inference. Quantization reduces the model size while also providing up to 3x lower latency with a little degradation in model accuracy and memory mapped method doesn’t allocates an area of memory on the heap and then copying bytes from disk into it and speeds loading and reduces paging.
")
")
SECTION II: DeepSpeech (Speech to Text conversion)

Output
"She sells seashells on the sea shore"
SECTION III : Tacotron (Text to Speech Synthesis)
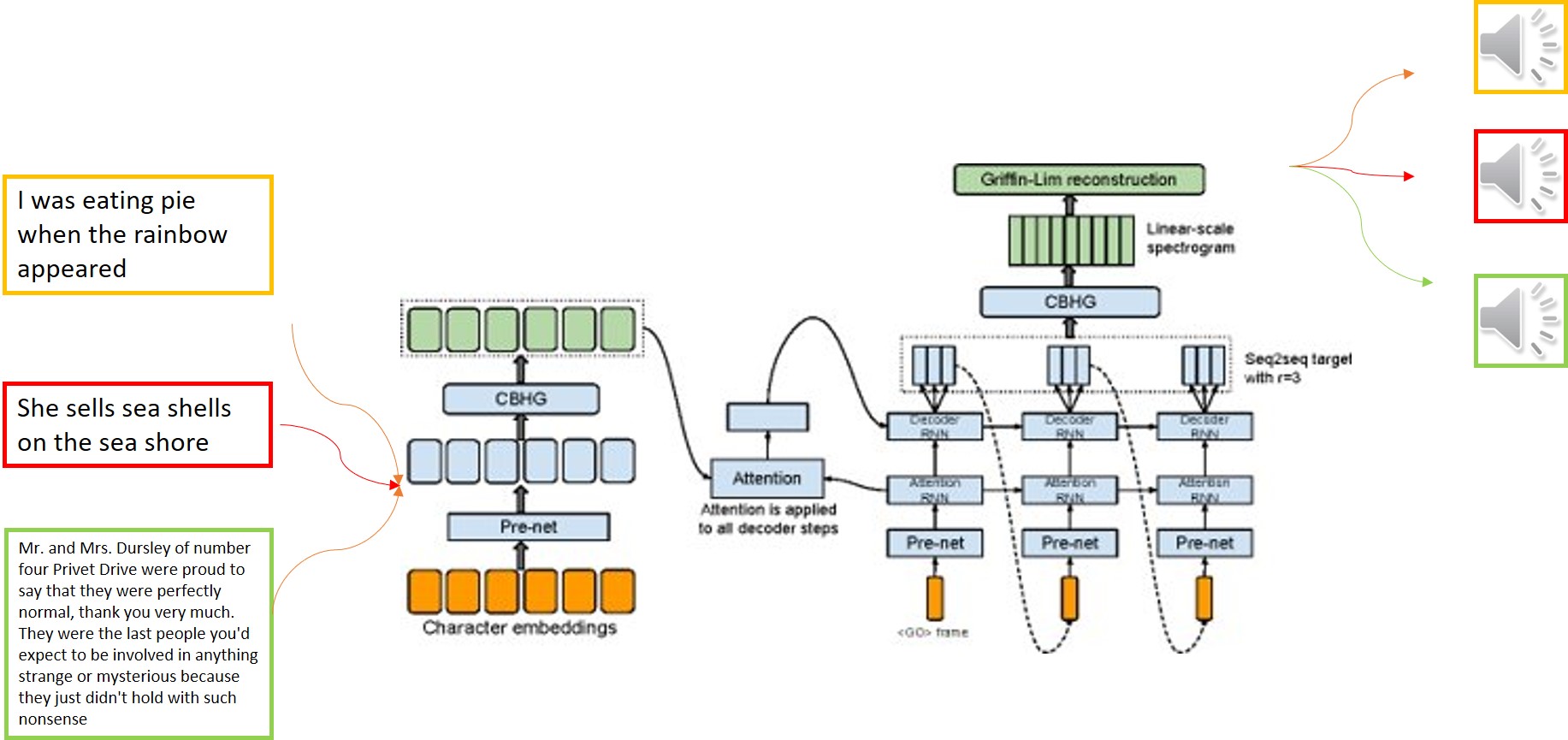
Tacotron Model Architecture[from paper titled "Tacotron:Towards end to end speech synthesis"]
Input to the network
I was eating pie when the rainbow appeared
Output audio
Input to the network
Mr. and Mrs. Dursley of number four Privet Drive were proud to say that they were perfectly normal, thank you very much. They were the last people you'd expect to be involved in anything strange or mysterious because they just didn't hold with such nonsense
